Generative Adversarial Networks GANs [1] have long dominated the Generative AI (GenAI) landscape. However, with the recent surges in the use of transformers [2] and diffusion models [3], the GANs have slowly begun to fade away.

However, recently Pan et al. introduced ‘Drag your GAN (DragGAN)’ paper [4], which has brought attention back to the GANs. The authors present a novel pipeline for spatial manipulation of GAN-generated images in the paper. The figure below shows an example demo of how the DragGAN works. You can manipulate the generated images using two points: the handle point and the target point. The DragGAN algorithm generates the edited image by moving the handle point towards the target point. More video demos are available on the project-page.

GANs
Now, let us dive into the details of this algorithm pipeline from the basics. It all started with the original GAN paper published by Goodfellow et al. [1], deriving from Game theory concepts. As the name suggests, the GAN architecture has two parts: A Generator and a Discriminator (see the figure below). Both these networks are adversarially trained to outperform (fool) each other. The generator tries to generate synthetic images that look real as possible. On the contrary, the discriminator that takes as inputs the synthetic and a real image tries to distinguish between them. Ideally, when the training stabilises, the generator would have learned to generate synthetic images which are indistinguishable from the real images. Initially, a simple min-max loss function was used for training, but later more sophisticated loss functions, such as the Wasserstein loss function [5, 6], were introduced.

StyleGAN
The following were the golden years for GANs. Several new alphabet GAN architectures were proposed with improved image generation capabilities. In 2019, Nvidia introduced StyleGAN, generating considerable hype in the field. The main contribution was in the generator architecture of the GAN pipeline.

Until then, the generator architectures were largely ignored. Most works contributed to modifying the discriminator architecture and formulating more sophisticated loss functions. StyleGAN introduced several novel contributions to the generator architecture, which are summarised below.

- Base Network: The authors used Progressive GANs (ProGAN) [7] as the base network architecture. The key concept of the ProGANs was to train the generator and the discriminator progressively. It starts with a smaller network trained to generate low-resolution images. Then the layers were added progressively and were trained to generate more fine-grained higher-resolution images. This stabilised the GAN training and produced higher-quality synthetic images.
- Mapping Network: Traditionally, the latent code (z ∈ Z) is fed directly to the generator. Assume that each factor in z controls image attributes like pose, expression, colour etc. Hence the sampling probability of a combination of factors in z should be the same as the density of the combination of corresponding attributes in the training dataset. This introduces entanglement in the latent space, thereby hindering the generator's image-generation capabilities. In StyleGAN, a learned constant feature vector is used as the input. The initial latent vector z is first projected into an intermediate feature space (W) via a mapping network (f: Z → W) and then fed to the generator at different scales, as shown in the figure above. Unlike Z, the intermediate space W is not bound by a fixed distribution which makes the factors of variations in the latent code w disentangled and linear. The experiments reported in the paper show that this indeed is the case and improves the image synthesis capabilities of the generator.
- Adaptive Instance Normalisation (AdaIN): The latent code w is fed to the generator at different scales via the AdaIN [8] mechanism, motivated by the Neural Style Transfer [9] literature. Learned affine transforms from w called styles (ys, yb) are injected into the generator using the following equation after each block of convolutional layers. Each feature map (xi) is normalised individually and then scaled and biased with the corresponding ys and yb, respectively.
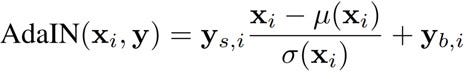
4. Noise Injection: A common artifact observed in the GAN-generated images then was the repetition of the non-identity-related attributes. For example, in the case of faces, this could be the exact placement of hair strands or skin pores. One reason for this is the inability of generator architecture to generate sufficient stochasticity from itself. StyleGAN overcame this by adding random noise to each feature map location at different layers. The generator can then use this noise to generate required stochastic variations in the generated images to avoid repetitive patterns.
The DragGAN is built on top of a pre-trained StylgeGAN, specifically the StyleGAN2 [10].
DragGAN
Now we dive deeper into the working of the DragGAN. The figure below illustrates the overall concept. The idea behind a DragGAN is the optimisation in latent space W to generate the required manipulated (edited) image. Let I be the original image, w the corresponding latent vector and I’ be the required edited output image. I’ can be obtained as I’=G(w*), where G is the pre-trained StyleGAN generator and w* is the latent code corresponding to I’. Thus the image manipulation (editing) problem becomes an optimisation problem to find w* in the latent space W.

The DragGAN algorithm has two parts: A) motion supervision and B) point tracking.
A) Motion Supervision: The main part of the DragGAN is to supervise the motion of the handle point p (w.r.t figure below) towards the corresponding target t. The idea is to supervise a small patch around p (red circle) to move towards t by a small step (blue circle). The loss function L(w) is optimised to obtain the required w*. The second term in the loss function weighed with λ, ensures that the points outside the user-defined mask will not be affected. The use of masks helps to localise the editing changes and constraints the search of w* in the latent space.

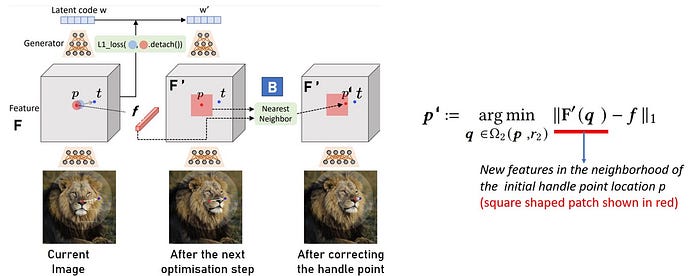
B) Point Tracking: New intermediate images are generated after every optimisation step, as shown in the figure below. Hence it is essential to keep track of the handle point location in each intermediate step to make sure that the correct point is shifted. The easiest method is using some SoTA pixel tracking methods like RAFT [11] or PIP [12] at the image level. However, the authors show that tracking the handle point(s) in the feature space yields better performance. With reference to the figure below, let f be the feature vector corresponding to the current handle point location p and F’ the new feature map. Then the new handle point location p’ is obtained by searching for the matching feature in F’ around the neighbourhood of p. Results from the paper show that this simple nearest-neighbour search in the feature space provides accurate results compared to the image-based pixel tracking methods.
Results reported in the paper and the supplementary demo videos show that the proposed DragGAN method is robust and reliable for spatially manipulating StyleGAN-generated images. An interesting application of the work is its extension to real images. Instead of using synthetic images, the method can be used on real images. The image has to be first projected into the latent space W using some GAN Inversion [13] technique. Once the corresponding latent space embedding is obtained, then the DragGAN method can be applied as usual. The figure below shows some examples of editing real images.

Summary
Even though transformers and diffusion models have taken over the GenAI field, interesting applications still exist using GANs. Especially applications making use of the latent space representations (both z and w) are to be explored further. A key drawback of the GANs w.r.t the diffusion models is the lack of performance on diverse datasets [14]. However, this may not be a fundamental limitation of the GAN architecture itself, but possibly the right training strategy has not yet been invented!
The article is based on my recent talk with the same title. Slides are available.
References:
[1] Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S, Courville A, Bengio Y. Generative adversarial nets. Advances in neural information processing systems. 2014;27.
[2] Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, Kaiser Ł, Polosukhin I. Attention is all you need. Advances in neural information processing systems. 2017;30.
[3] Ho J, Jain A, Abbeel P. Denoising diffusion probabilistic models. Advances in neural information processing systems. 2020;33:6840–51.
[4] Pan, X, Tewari, Leimkuhler, T, Liu, L, Meka, A, Theobalt, C. Drag Your GAN: Interactive Point-based Manipulation on the Generative Image Manifold. In ACM SIGGRAPH 2023 Conference Proceedings 2023.
[5] Arjovsky M, Chintala S, Bottou L. Wasserstein generative adversarial networks. In International conference on machine learning 2017 Jul 17 (pp. 214–223). PMLR.
[6] Gulrajani I, Ahmed F, Arjovsky M, Dumoulin V, Courville AC. Improved training of wasserstein gans. Advances in neural information processing systems. 2017;30.
[7] Karras T, Aila T, Laine S, Lehtinen J. Progressive Growing of GANs for Improved Quality, Stability, and Variation. In International Conference on Learning Representations 2018.
[8] Huang X, Belongie S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE international conference on computer vision 2017 (pp. 1501–1510).
[9] Jing Y, Yang Y, Feng Z, Ye J, Yu Y, Song M. Neural style transfer: A review. IEEE transactions on visualization and computer graphics. 2019 Jun 6;26(11):3365–85.
[10] Karras T, Laine S, Aittala M, Hellsten J, Lehtinen J, Aila T. Analyzing and improving the image quality of stylegan. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition 2020 (pp. 8110–8119).
[11] Teed Z, Deng J. Raft: Recurrent all-pairs field transforms for optical flow. InComputer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part II 16 2020 (pp. 402–419). Springer International Publishing.
[12] Harley AW, Fang Z, Fragkiadaki K. Particle video revisited: Tracking through occlusions using point trajectories. In European Conference on Computer Vision 2022 Oct 23 (pp. 59–75). Cham: Springer Nature Switzerland.
[13] Daniel Roich, Ron Mokady, Amit H Bermano, and Daniel Cohen-Or. 2022. Pivotal tuning for latent-based editing of real images. ACM Transactions on Graphics (TOG) 42, 1 (2022), 1–13
[14] Dhariwal P, Nichol A. Diffusion models beat gans on image synthesis. Advances in neural information processing systems. 2021 Dec 6;34:8780–94.
